数据准备公式
1. 使用场景
数据准备是宜搭低代码平台中的一项关键功能,旨在帮助企业用户在进行数据分析和应用前对原始数据进行清洗、融合和转换。数据准备采用零代码ETL(Extraction Transformation Loading)方案处理来自宜搭内应用、企业外部数据库、文件型数据以及钉钉官方数据源(支持花名册、OA、智能人事、考勤等)的数据,通过构建数据加工流程,将零散数据整合为标准化数据集,以满足可视化分析和数据化决策的需求。
2. 数据准备介绍
3. 设置公式入口
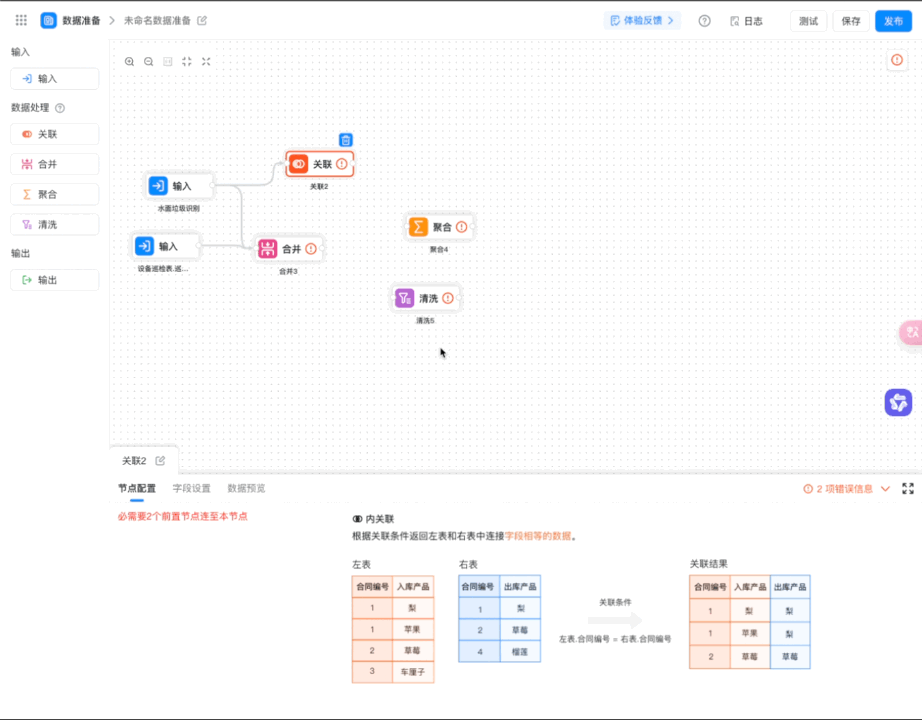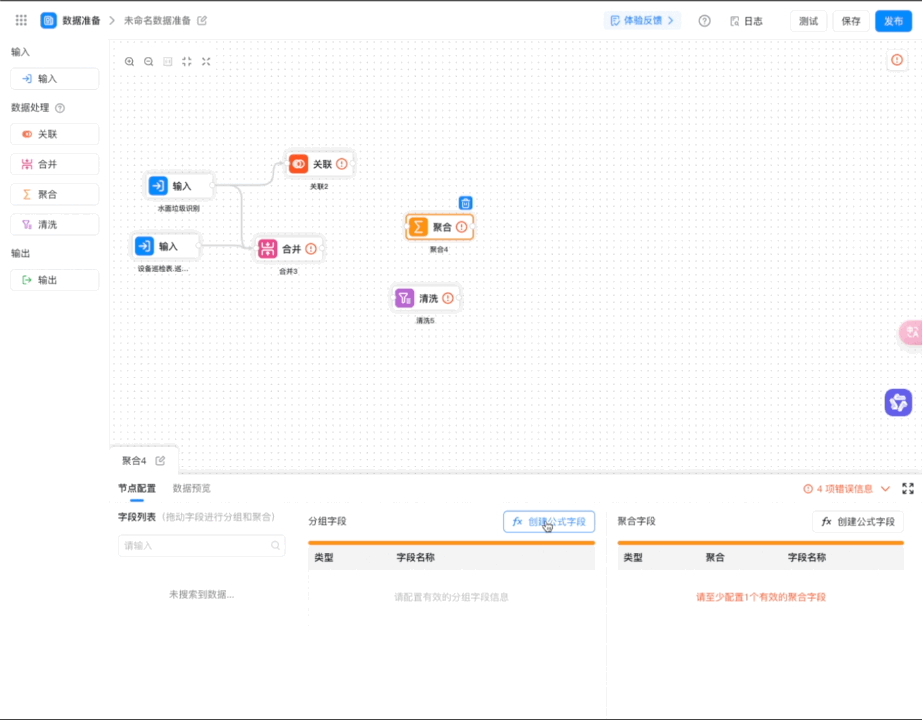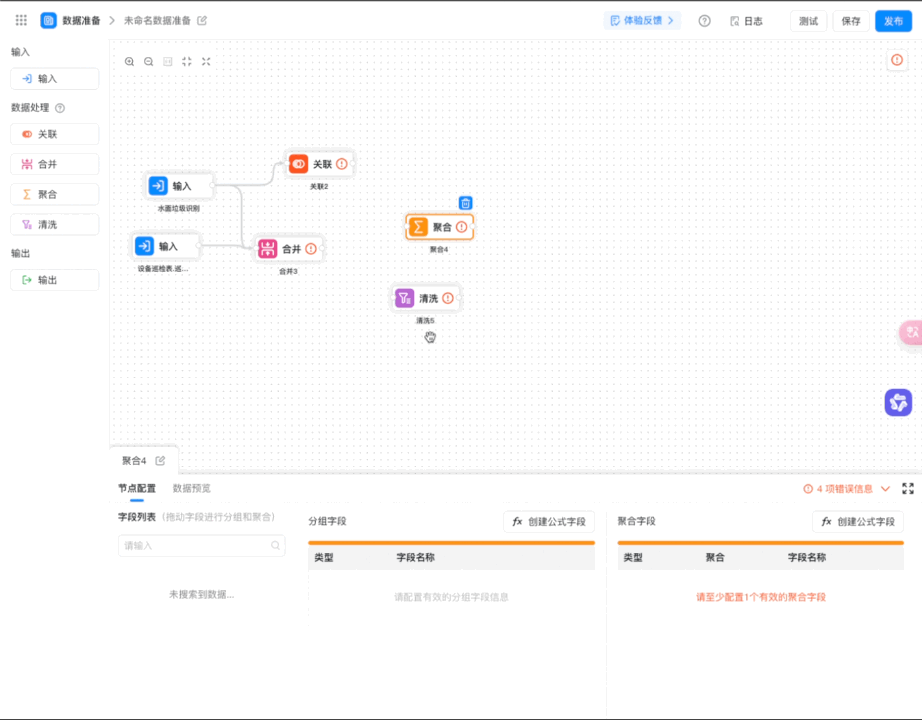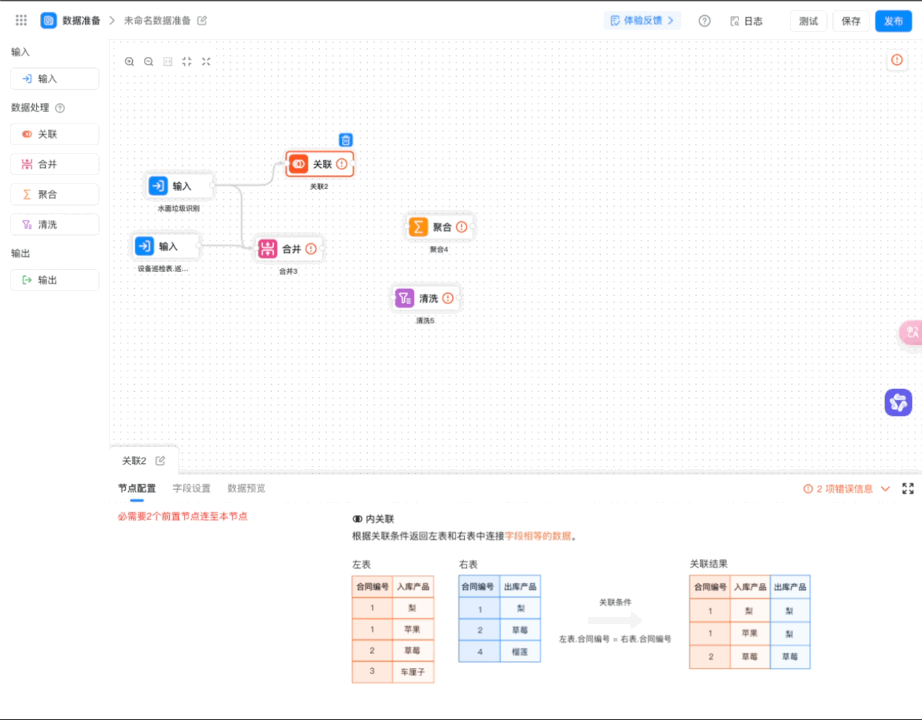
路径:应用设置 > 数据工厂 > 数据准备>新建数据准备>选择数据集,选择关联节点、聚合节点、清洗节点,均需选择公式。
查看以下视频进行设置:
4. 逻辑处理类
CASEWHEN
用法1:CASEWHEN(<条件>,<值>,<条件>,<值>.....), 类同SQL中的case when语法
示例:CASEWHEN(<性别字段>="男","male",<性别字段>="女","female"),则该字段值为"男"的被替换为"male","女"替换为"female"
用法2:CASEWHEN(<条件>,<值>,<条件>,<值>.....<值>), 类同SQL中的case when语法
示例:CASEWHEN(<性别字段>="男","male","female"),则该字段值为"男"的被替换为"male",非"男"替换为"female"
5. 文本处理类
LEN
用法:LEN([字符串字段]),函数返回为字符串的长度
示例:LEN("test"),返回值为4;LEN("测试"),返回值为2,一个中文对应1个英文字符。
LEFT
用法: LEFT(<度量字段>,< n >), 函数返回<字段>值从左边第1个字符开始,长度为n的字符串
示例: LEFT(字段1,3) 返回值为"ABC";字段1的值为"ABCDEF";
RIGHT
用法: RIGHT(<度量字段>,< n >), 函数返回<字段>值从右往左数的长度为n的字符串
示例:RIGHT(字段1,3) 返回值为"DEF";字段1的值为"ABCDEF";
MID
用法:MID(<度量字段>, < start >, < n >), 函数返回<字段>值从从左边第start个开始, 长度为n的字符串
示例:MID(字段1, 3, 3) 返回值为"CDE";字段1的值为"ABCDEF";
POS
用法:POS(<度量字段>,<字串>), 函数返回<字串>在<文本>中的位置, 如无匹配则返回0;
示例:POS(字段1,"DE") 返回值为4;字段1的值为"ABCDEF";
UPPER
用法:UPPER(<度量字段>), 将<字段>的值转换成大写;
示例:UPPER(字段1) 返回值为"ABCDEF";字段1的值为"AbcdeF";
LOWER
用法:LOWER(<度量字段>), 将<字段>的值转换成小写;
示例:LOWER(字段1) 返回值为"abcdef";字段1的值为"AbcdeF";
VAL
用法:VAL(<度量字段>), 将<字段>文本类型转换成数值类型
示例:VAL(字段1) 返回值为 123;字段1的值为"123";
LEFTTRIM
用法:LEFTTRIM(<度量字段>), 去掉<字段>左边的空格后返回
示例:LEFTTRIM(字段1) 返回值为"ABC";字段1的值为" ABC";
RIGHTTRIM
用法:RIGHTTRIM(<度量字段>), 去掉<字段>右边的空格后返回
示例:RIGTTRIM(字段1) 返回值为"ABC";字段1的值为"ABC ";
NUMBERTOSTRING
用法:NUMBERTOSTRING(<数值>), 数值类型的数据转换成字符串
示例:NUMBERTOSTRING(字段1) 返回值为"12345";字段1的值为"12345 ";
SPLITPART
用法:SPLITPART(<字符串字段>,分隔字符,子串位置), 公式会将一个字符串按照“分隔字符”将其分为N个子串(N等于分隔字符的数量+1),子串位置从1(从左往右)开始计数,或者从-1(从右往左)开始计数
示例:SPLITPART(<字段1>,A,2) 返回值为"BCD";字段1的值为"ABCDABHABC";子串位置填写-5时,也可以取到"BCD"
CONCAT
用法:CONCAT(<字段>,<字段>,.....), 公式会将多个字段连接为一个字符串。入参必须为字符串类型的字段
示例:CONCAT(<字段1>,<字段2>) 返回值为"ABCD";字段1的值为"A",字段2的值为"BCD"
REPLACE
用法:REPLACE([字符串], [搜索字符串], [替换字符串]), 函数返回为替换后的字符串
示例:REPLACE([字段1], [字段2], [字段3])返回值为"a12345efg";字段1的值为"abcdefg",字段2的值为""bcd",字段3的值为"12345".
6. 时间处理类
NOW
用法:NOW(),获取当前时间,会精确到秒
示例:略
DATEFORMAT
用法:DATEFORMAT(<日期字段>,<时间格式>),将日期格式化成字符串
以上两个函数的format格式目前统一为java 中格式化保持一致,支持格式类型如下:
- yyyy:年
- MM:月
- dd:日
- hh:1~12小时制(1-12)
- HH:24小时制(0-23)
- mm:分
- ss:秒
示例1:
DATEFORMAT(<日期字段>,"yyyy-MM-dd"),若日期字段有个值为1989年8月4日,则返回值为1989-08-04,格式化时,也可以将"-"改为"/"等字符。
示例2:
DATEFORMAT(<日期字段>,"yyyy-MM-dd HH:mm:ss"),若日期字段有个值为2020年9月1日下午1点30分整,则返回值为2020-09-01 13:30:00,格式化时,也可以将连接符号"-"、“:”改为"/"、“年”、“月”、“日”等字符。
DATEADD
用法:DATEADD(<时间字段>,<偏移量>,<时间粒度>),在<时间字段>的基础上增加<时间粒度>的<偏移量>。
- 时间粒度取值:
- YEAR:年
- MONTH:月
- DAY:日
- HOUR:时
- MINUTE:分
- SECOND:秒
- 偏移量是需要增加或减少的具体数字,取值为正则表示增加,取值为负则表示减少。
示例1:
假设表单中日期组件的取值为"20200901",那么DATEADD(日期组件,10,"DAY") = 20200911。
示例2:
假设表单中日期组件的取值为"20200901",那么DATEADD(日期控件,-1,"DAY") = 20200831。
日期展示格式默认为yyyyMMdd,如需需要修改日期的展示格式可以参考DATEFORMAT函数的示例。
DATEDIFF
用法:DATEDIFF(<时间字段1>,<时间字段2>,<时间粒度>),返回的结果为时间段字段1减去时间段字段2在时间粒度上的差值。
时间粒度可选值为:
- YEAR 年
- MONTH 月
- DAY 日
- HOUR 时
- MINUTE 分
- SECOND 秒
示例:DATEDIFF(日期组件1,日期组件2,"DAY"),返回值为2个日期组件相差天数
注意:参数仅支持日期组件,无法在公式输入固定日期值。
假设表单中日期控件的日期值为“2020-02-14”,假设今天为“2020-02-16”,那么使用
DATEDIFF(NOW(),填写日期,"DAY") = 2,
DATEDIFF(填写日期,NOW(),"DAY") = -2
FROMUNIXTIME
用法:将数字型的unix时间日期值unixtime转为日期值
函数声明:
datetime fromunixtime(bigint unixtime)
参数说明:
- unixtime:Bigint类型,秒数,unix格式的日期时间值,若输入为string,double,decimal类型会隐式转换为bigint后参与运算。
- 返回值:Datetime类型的日期值,unixtime为NULL时返回NULL。
示例:
fromunixtime(123456789) = 1973-11-30 05:33:09
WEEK
用法:WEEK([日期], [起始日(可以不指定)]), 计算日期年份中的哪一周, 起始日不指定,默认一周的第一天是周一,起始日的值为:1-7 分别表示周一为第一天.... 周日为第一天
示例:WEEK([日期],)返回值为"20202";字段的值为"2020-01-08",起始日可以不指定,默认为空。
QUARTER
用法:QUARTER([日期], [是否是财年(可以不指定)]), 计算日期年份中的哪一季度, 是否是财年:1表示按照财年统计(4月份), 0表示按照自然年
示例:QUARTER([字段1], 0)返回值为"1";字段1的值为"2020-02-02"
7. 基础统计类
ROUND
用法:ROUND(<字段>,<精度>), 四舍五入地对字段进行小数位数调整
示例:ROUND(<字段1>,<精度>) 返回值为"12.33";字段1的值为"12.33333",精度为2
MOD
用法:MOD(<字段>,<字段>), 取模(取余)运算,返回取模值(或余数)。
说明:若要获得除法的商,可使用/ 四则运算符,比如 6/4 得到 商1余2。
示例: MOD(<字段1>,<字段2>) 字段1的值为"6",字段2的值为"4",返回值为"2";
ParseDouble
用法:ParseDouble(<字段>),字符串或整数强转浮点数
示例:ParseDouble(<字段>),如果字段的值是3或“3”,则结果3.0
ParseInt
用法:Parselnt(<字段>),字符串或浮点数强转整数
示例:Parselnt(<字段>),如果字段的值是3.2或“3.2”,则结果3
8. 数组类
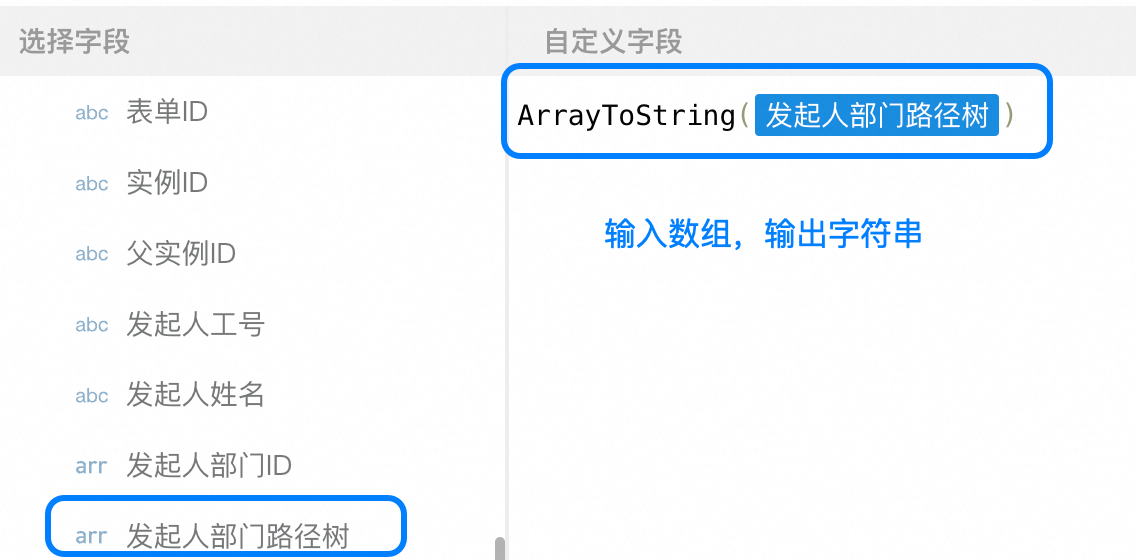
ArrayToString
用法:ArrayToString(<数组字段>,[分隔符可选]),将数组转换为字符串
示例:ArrayToString(<字段1>,<字段2>) 返回值为"产品部-技术部-业务部";字段1的值为"[产品部,技术部,业务部]",字段2的值为"-";若字段2的值为空,则返回"产品部,技术部,业务部"
StringToArray
用法:StringToArray(<数组字段>,[分隔符可选]),将字符串解析为数组
示例:StringToArray(<字段1段>,<字段2>) 返回值为"[产品部,技术部,业务部]";字段1的值为"产品部-技术部-业务部",字段2的值为"-"

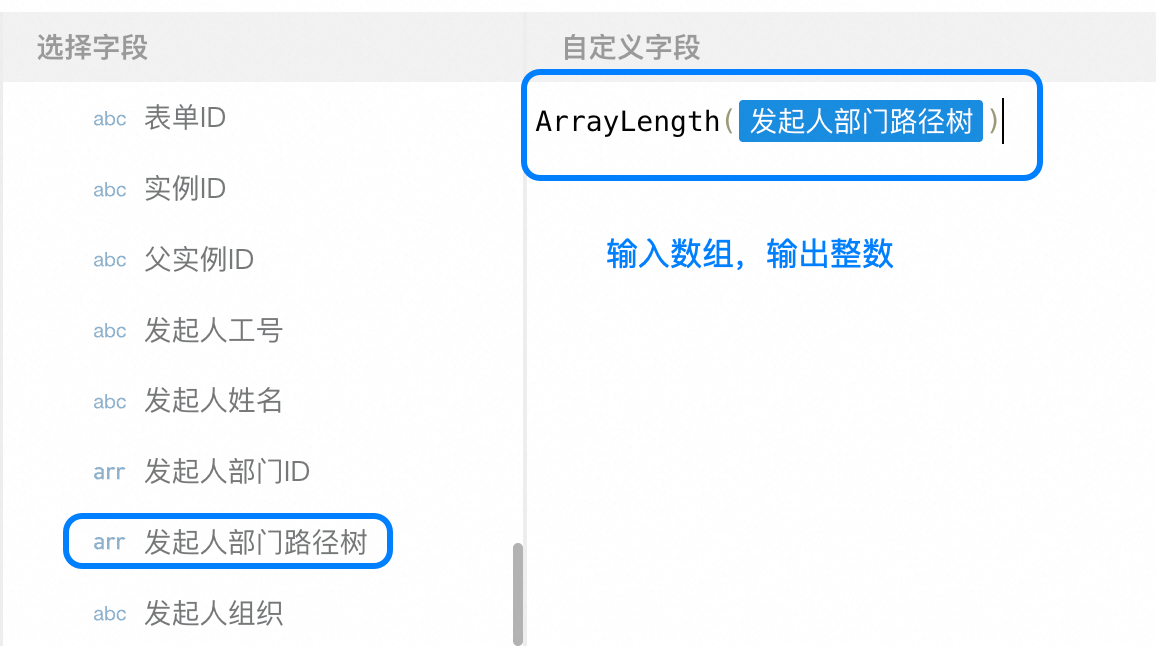
ArrayLength
用法:ArrayLength(<数组字段>),返回数组长度
示例:ArrayLength(<多选等数组字段>)返回值为"3";字段的值为"部门",其选项为"产品部,技术部,业务部"
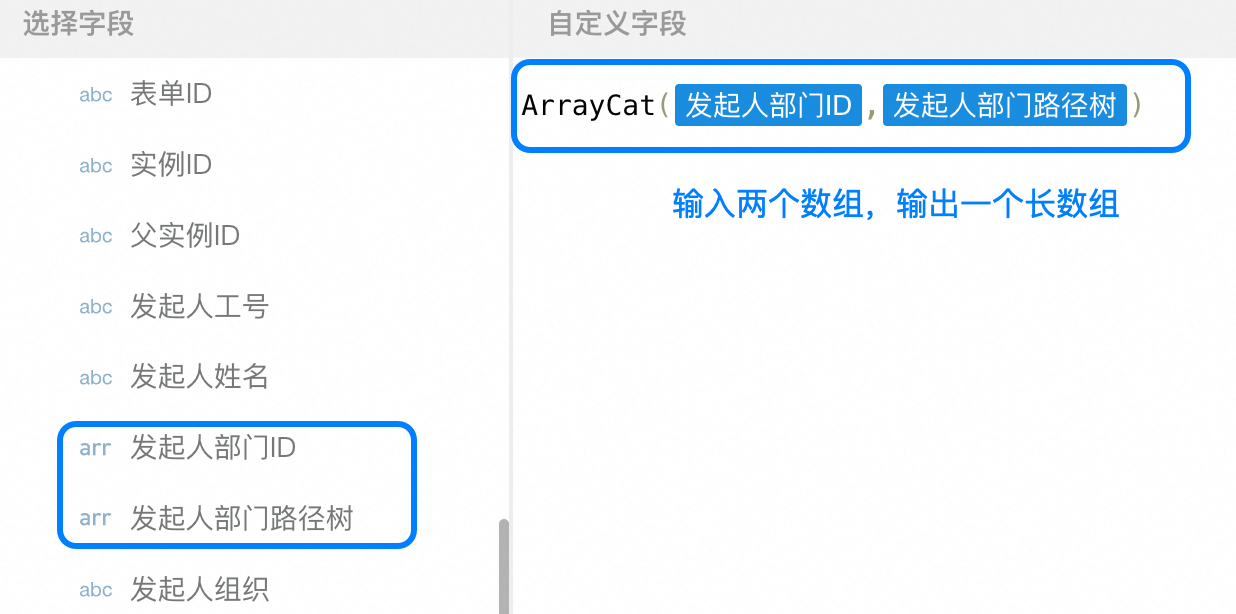
ArrayCat
用法:ArrayCat(<数组字段1>,<数组字段2>,...),返回多数组拼接格式
示例:ArrayCat(<多选等数组字段1>,<多选等数组字段2>,...)返回值为"产品部,技术部,业务部,产品人员,技术人员,业务人员";字段1的值为"产品部,技术部,业务部",字段2的值为"产品人员,技术人员,业务人员"